At present, cities around the world are facing the great challenge of disaster risk management with the emergence of constantly changing buildings and facilities. An understanding of the specific location of buildings and facilities and the potential risk of disaster damage is a key task of disaster risk management (DRM). The Global Foundation for Disaster Reduction and Recovery (GFDRR) saw the great potential of the combination of deep learning and geospatial technologies in disaster risk management, and launched the competition named The Open Cities AI Challenge: Segmenting Buildings for Disaster Resilience.
The competition aimed to develop an accurate and usable spatial deep learning AI model, which can be used to identify buildings from drone aerial images of African cities, and then used to draw disaster risk management maps of cities to improve disaster resilience. The work of GeoAI team of SuperMap Research Institute achieved good results, and in this article, we will combine the SuperMap winning work, take the semantic segmentation of high-resolution image buildings as an example, and introduce the implementation of semantic segmentation and various optimization methods.
Semantic segmentation
First, let’s briefly introduce what semantic segmentation is. Computer vision is a popular research direction of deep learning and has a wide range of applications in face recognition, image retrieval, autonomous driving and other fields. Semantic Segmentation is a basic task in computer vision, and its goal is to classify the categories to which each pixel of an image belongs, so that different types of objects can be distinguished on the image.

Original image (left), semantic segmentation (right)
Note: Example image from Stanford Background Dataset
Semantic segmentation is widely used in autonomous driving, medical image analysis and robotics. Its application in geographic information image analysis scenarios is mainly through training deep neural network models to allow machines to identify roads, rivers, buildings, etc. from images.
Implementation process
Semantic segmentation technology based on deep learning recognizes buildings in images, mainly including data preparation, model construction, and model inference. SuperMap provides us with GeoAI process tools to complete spatial deep learning projects, supports complete task implementation process, can help to quickly build AI models suitable for their respective businesses, and obtain inference results.
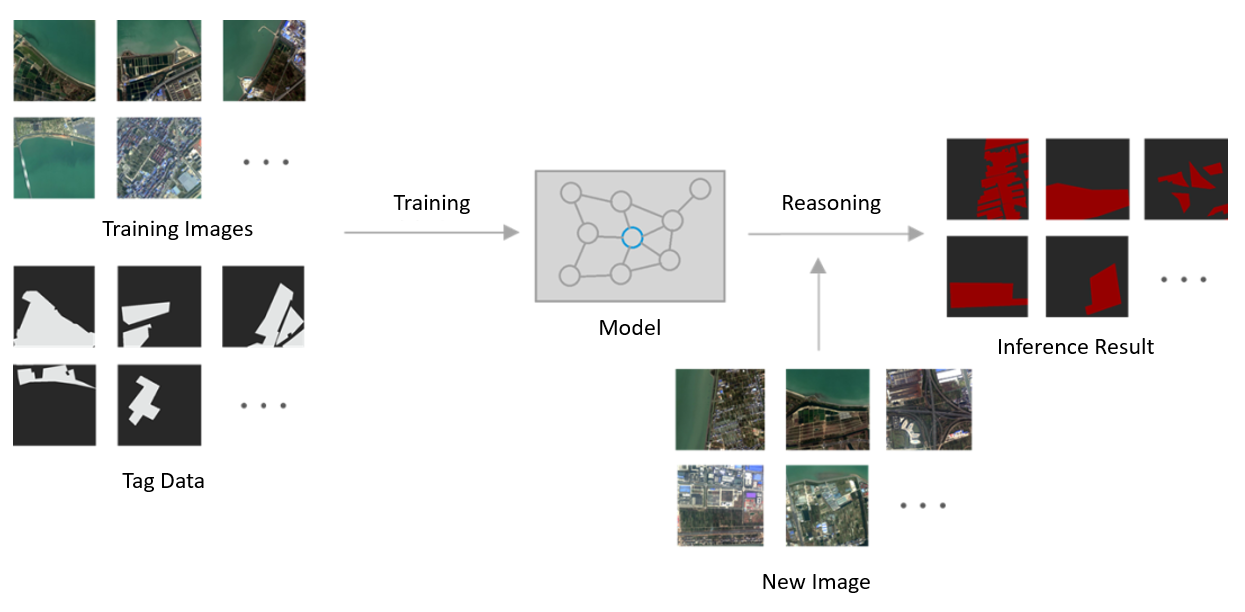
Spatial deep learning implementation process
Data situation
1. Training data: image blocks containing buildings (about 20,000) and image blocks without buildings (about 50,000), the number of image blocks is 1024, and the resolution is 0.02-0.2m; The vector label data corresponding to the block.
2. The test data are image blocks (about 10,000 images) distributed in different regions of Africa, and the number of rows and columns is 1024.
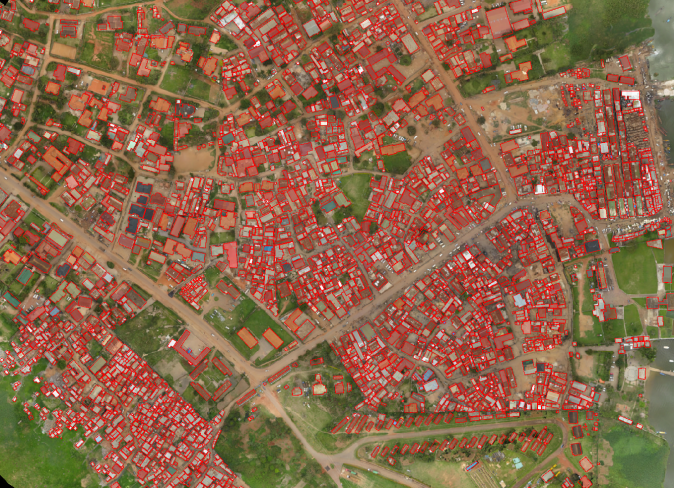
Example of training data (image data with vector labels)
Model selection
There are many models that can be used for image semantic segmentation, including FPN, FCN, U-Net, PSPNet, DeepLab series, etc. When selecting a segmentation model, it is necessary to select an appropriate model according to the project requirements. In this project, we finally choose the FPN model by comparing the accuracy and efficiency. Among them, EfficientNet is used as the backbone network to extract basic image features, and FPN can further process the features extracted by EfficientNet.
1. EfficientNet
In 2019, Google proposed a new type of convolutional neural network, EfficientNet, with efficient image feature extraction capabilities. Convolutional Neural Networks (CNN) are usually developed under a fixed resource budget and then scaled up as more resources are added to achieve higher accuracy. EfficientNet utilizes simple and efficient compound coefficients to uniformly scale multiple dimensions of the model, effectively improving the accuracy and efficiency of the model.
Choosing a suitable backbone network can make the model extract image features better and more efficiently. In semantic segmentation, commonly used backbone networks also include ResNet, VGG, DenseNet, etc.
2. FPN
FPN (Feature Pyramid Network) is a model that efficiently extracts features of various scales in pictures, which can make the final output features better represent the information of each dimension of the input picture. Essentially, it is a method to enhance the feature representation of the backbone network.
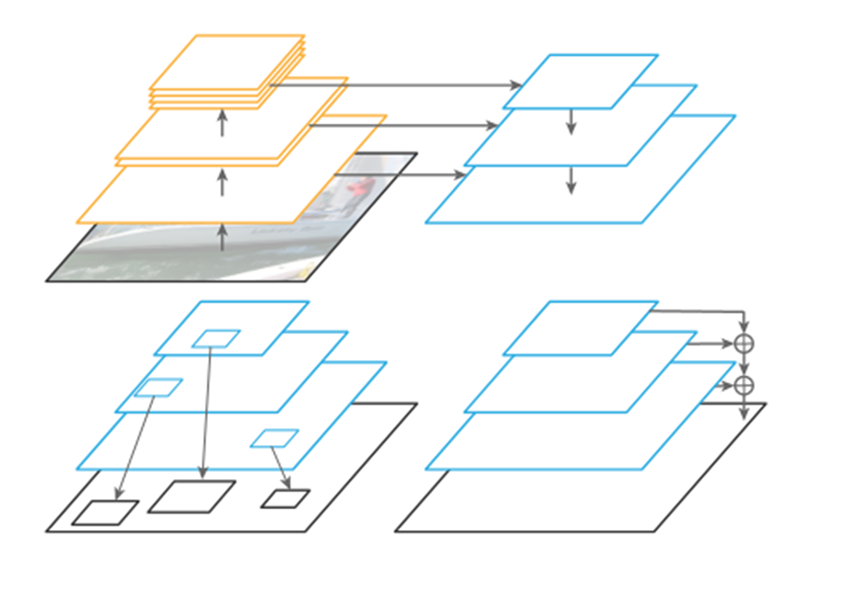
FPN basic architecture (Image source: Panoptic Feature Pyramid Networks)
Optimization Strategy
In order to improve the overall performance of the model, we have carried out targeted optimization from the aspects of data, training strategy and inference process. The following will focus on several optimization methods that can significantly improve training efficiency and inference accuracy:
Data optimization
1. Data enhancement
In a deep learning project, generally the more data there is, the better the training task will be. Data augmentation can generate more effective training data from limited data, increase the amount of training data, and improve the generalization ability of the model. In the process of data optimization, various data enhancement methods such as cropping, scaling, and rotation can be used.

Data enhancements
2. Add negative samples
The training data (such as cultivated land) in the non-building area is added to the sample as a negative sample, which can reduce the situation that non-building areas such as cultivated land are discriminated as buildings during training, thereby improving the inference accuracy. As shown in the figure below, when negative samples are added, there will be no inference as a building (yellow area).
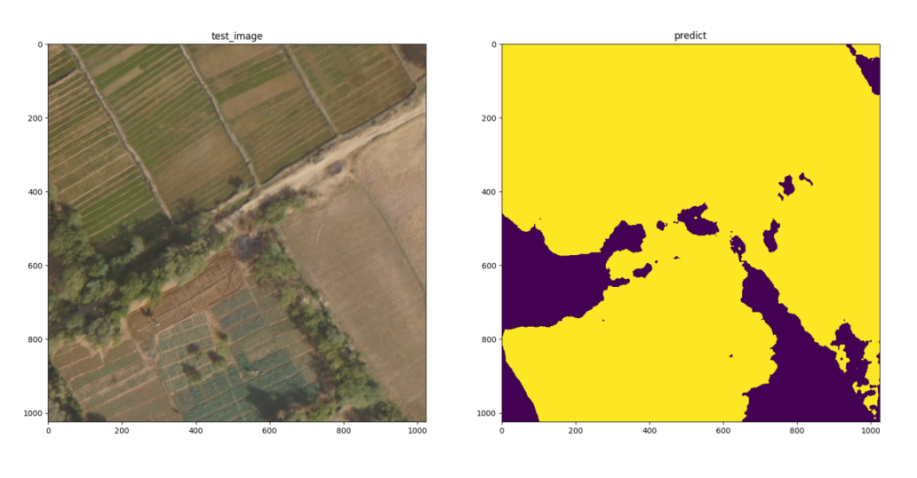
Image to be reasoned (left), misjudgment of cultivated land reasoning (right)
Training optimization
1. Optimizer
In order to make the model output approach the optimal value, we need to use various optimization strategies and algorithms to update the network weight parameters that affect model training and output. Usually, we refer to the algorithm for updating the parameters as the optimizer, which algorithm is used to optimize the network weight parameters.
Some commonly used optimizers:
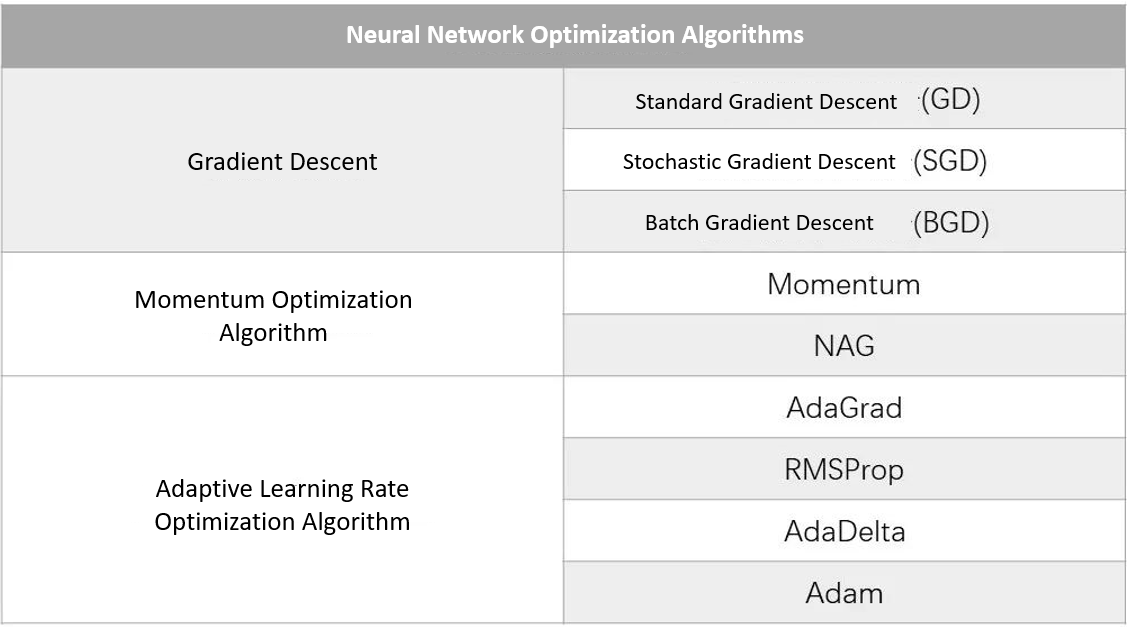
As shown in the above table, the gradient descent method is the most basic type of optimizer; the momentum optimization method is an improvement on the basis of the gradient descent method; the adaptive learning rate optimization algorithm is optimized for the learning rate setting of the model training process, The effective adjustment of the learning rate can improve the training speed and effect.
In practical applications, it is necessary to select a suitable optimizer according to specific problems.
2. Multiple graphics cards
Multi-graphics card training can significantly improve the training efficiency, and at the same time, it can also improve the final accuracy and generalization ability of the model to a certain extent.
Inference optimization
1. Multi-scale image inference weighting
In the inference process, the image is enlarged and reduced, multi-scale images are used for inference, and the results are weighted and averaged to obtain the final output result. This optimization method can significantly improve the inference accuracy in application.

Multiscale Image Inference Weighting
After a series of optimizations, the final accuracy value IoU of the project on the test dataset is better than 0.83, that is, the buildings in the image can be segmented more accurately, reaching the level of practical application.
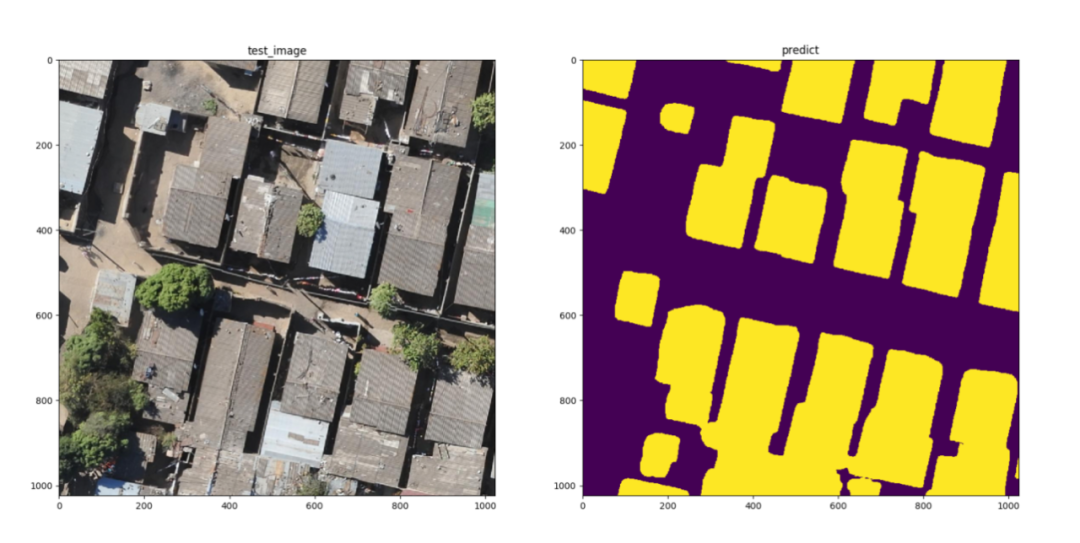
Inference result example
Intersection-over-Union (IoU): A standard metric for evaluating the performance of semantic segmentation algorithms. This criterion is used to measure the correlation between the true range and the predicted range, the higher the correlation, the higher the value.
As shown in the figure below, the green line is the correct result of human marking, and the orange line is the result predicted by the algorithm. The IoU measurement criterion is the result of dividing the area of the overlapping part of the two regions by the area of the aggregate part of the two regions. Generally speaking, IoU>0.5 can be considered as a good result.
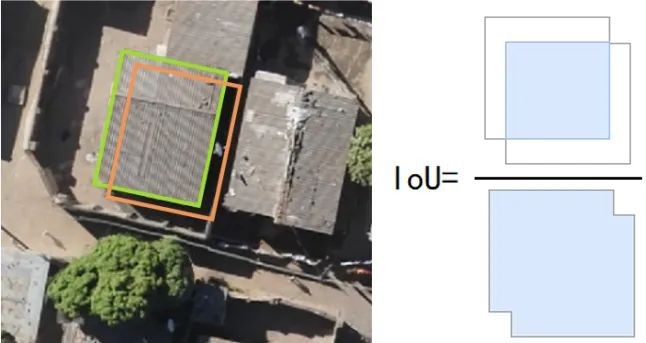
IoU calculation principle
Summary
More and more practical application scenarios need to infer relevant semantics or knowledge from images, and deep learning is an effective technology to solve these scenarios. Taking the semantic segmentation of high-resolution image buildings as an example, this article introduces the implementation of semantic segmentation and different optimization methods in terms of data, training and inference processes, and provides a practical reference for building effective deep learning projects.
Author: Zheng Meiling, SuperMap Research Institute




