AI technology can be applied in the field of GIS from the perspectives of Data Mining, Natural Language Processing and Computing. It can provide functions of spatial density clustering and intelligent identification of address elements, the extraction of buildings’ underside images and detection of target image to solve the difficulties in traditional GIS applications, and make GIS applications smarter.
Machine Learning
Spatial Density Clustering
Today, with the rapid development of Internet technology, human beings produce more and more data, and the data is becoming more and more difficult to manage. The spatial density clustering function of SuperMap GIS 9D (2019) can categorize huge point data sets into clusters and explore the value in the data through spatial location information. It offers three different algorithms of DBSCAN, HDBSCAN and OPTICS, to suit the clustering needs in different situations.
Address Element Identification
With the development of GIS technology, the spatialization of non-GIS data, such as the need of business analysis, real estate, public security and logistics for “fast map” is increasing, it needs the corresponding technologies to solve the problem of spatialization of text data. The Geo-coding technology, which mainly includes two processes of address resolution and address matching, is the main technology to solve the spatialization of text data. In the early stage of the exploration, it focused on the core of the address analyzing process - address element identification, because address elements are important basis for Geo-coding.
The machine learning method can be used to upgrade the traditional address element identification method and to improve the matching rate, accuracy and scalability of address analyzing. The Conditional Random Fields (CRF) method in machine learning can be used to construct a model that specifically identifies geographic features and improve the recognition of address elements.
Deep Learning
The Extraction of Oblique Buildings’ Bottom Surface Images
In recent years, the drone technologies has developed more and more rapidly, as well as the new generation of 3D GIS technology. Through the Oblique Photogrammetry data collected by drones, the 3D reconstruction of realistic scenes has become an important direction of 3D GIS technology. However, the original Oblique Photogrammetry data is difficult to perform spatial query and analysis, and is not easy to manage. In most cases, it is necessary to extract the features of the oblique photogrammetry data by people, and to superimpose it with oblique photogrammetry data to achieve a queryable and analyzable effect.

The deep learning model is used to automatically extract the bottom surface images of the building from the oblique photogrammetry data and to optimize the singulation of the data. In deep learning, the Convolutional Neural Network (CNN) has always performs good in the image field. Therefore, the deep learning model can be built based on the U-Net network structure of CNN to complete the process of extracting the buildings’ underside in Oblique Photogrammetry data. By extracting the DOM and DSM from the Oblique Photogrammetry data, the model can automatically extract the bottom surface of buildings through DOM image information (RGB values) and DSM elevation information to generate vector data. The extraction results can be superimposed and stretched with oblique photogrammetry data in a 3D scene.
Target Image Detection
Identifying the specific land and objects on the image and performing spatial statistics and analysis to obtain the information of the target objects from the image has always been a concern in GIS and RS.
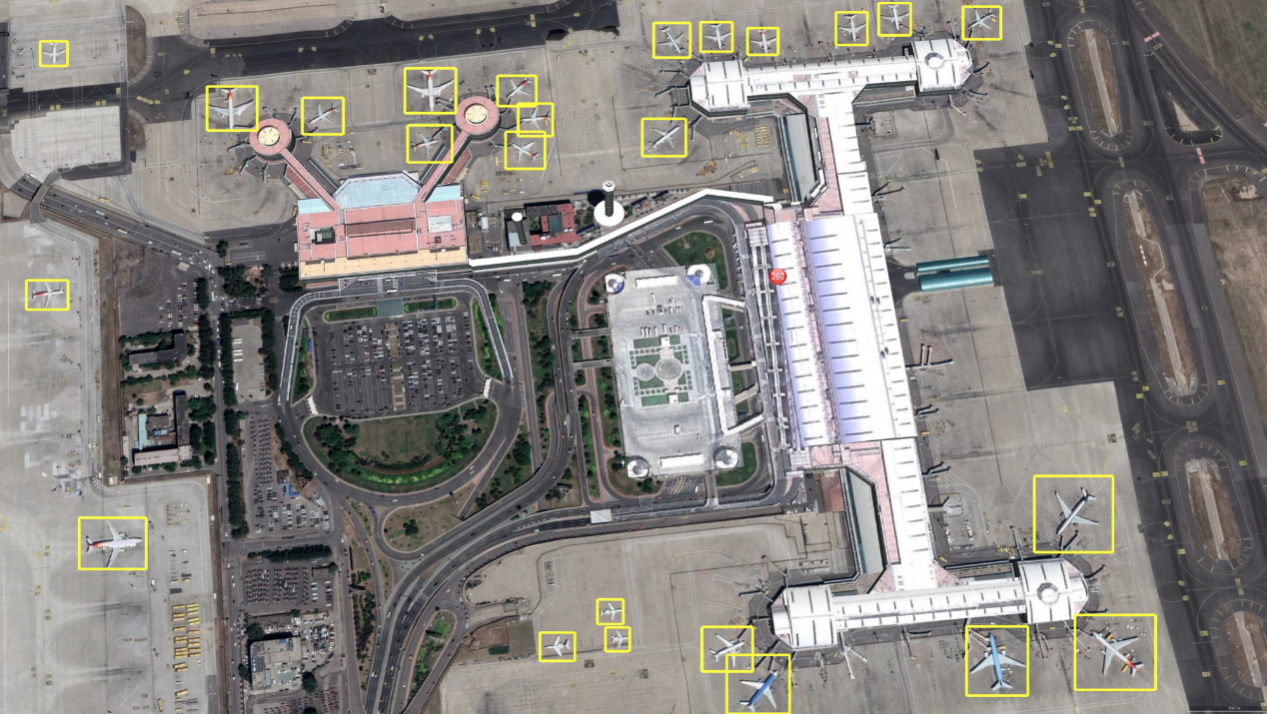
The method of deep learning can improve the target detection process of image data. Based on the CNN network, the faster and more accurate Faster-RCNN model is used and optimized. At the same time, the small target recognition is optimized for different sizes of similar targets that commonly used in remote sensing images to achieve better test results. The entire process only needs to input an image and determine the target category to quickly obtain the vector data of the target objects.